Kaggle 銅メダルへの道(3日目)
こんにちは、筋肉めがねです。
前回の記事では英語の勉強方法について、シャドーウィングという方法を使っていたと書きました。では、ドイツ語の勉強でシャドーウィングを使っていきたいんだけれども、どのマテリアルを使えば良いのか迷いますよね。僕のオススメはDeutsche Welleです。LEARN GERMAN直下のDeutsch Aktuellにスクリプト付きの動画が沢山あります。それを使ってドイツ語を勉強していきましょう。

それでは、本日もKaggleで銅メダルを取ることを目指して一つ一つ進めていきましょう。前回はKaggleからダウンロードしたデータをGoogle Driveに格納し、Google ColaboratoryからGoogle Driveへ格納したファイルを操作できるように環境を構築しました。
前回の記事で書いた通り、KaggleのCompetitionを進める上での流れは、大まかに以下の通りである、と書きました。
- 動作環境の構築
- KaggleからCompetitionデータを取得
- データ概要の把握、重複の確認
- 外れ値の削除
- 前処理:欠損値処理
- 前処理:変数変換
- 目的変数の分布の確認、処理
- 特徴量の選択
- 機械学習
- モデルをKaggleへ提出
本日は、3. データの概要の把握と4. 外れ値の削除まで進めます。
参考にしているのは、こちらのブログでございます。
A study on Regression applied to the Ames dataset | Kaggle
データ概要の把握
先ず、データを操作する前に、前回構築したGoogle Colaboratory上の環境に必要なライブラリをインストールします。
続いて訓練データの内容を見ていきます。

結果、1460行の物件があり、そしてIDを含めて81のカラム(情報の数)がある事がわかります。
そして、リストアップされている物件の中で重複があるかどうか、確認します。

重複はありませんでした。重複がない事が確認できたので、IDカラムは必要ありません。IDカラムを削除しましょう。
外れ値の削除
続いて外れ値を削除します。KaggleのHouse Pricing competitionへデータを提供した方の書いたオリジナルの文献によると、GrLivArea(床面積)が4000 square feet (371.6平米)以上の5つのデータのうち、3つは外れ値であり、2つは他のデータ群からはかけ離れた数値であるため、モデルを作るための訓練データとしては適切でない、とあります。よって、それらを訓練データから取りましょう。
http://jse.amstat.org/v19n3/decock.pdf
先ず、外れ値を削除する前に、1460の物件について、床面積と売価でプロットしたグラフを描画します。

続いて、床面積が4000 square meter(371.6平米)以上の5つのデータを取り除きます。
そして、改めて全ての物件について、床面積と売価でプロットしたグラフを描画します。

外れ値が除かれている事を確認できました。
次回の記事では、欠損値の処理から進めます。
それでは、本日は以上でございます。

Kaggle 銅メダルへの道(2日目)
こんにちは、筋肉めがねです。
さて、ドイツ語を話せるようになりたい、ということで、英語の勉強方法を振り返るという話でした。シャドーウィングでしたね。学生の当時、僕が使っていた教材はEnglish Journalでした。朝8時から研究室にこもって、ショーンKの渋いナレーションにリードされながら、毎日毎日、英語のインタビューを30分ぐらい聞いていたものです。イヤホンをつけ、例えばレオナルドディカプリオとインタビューアーのやりとりを聞きながら、その会話のスクリプトを読みながら、彼らと全く同じスピードで、同じ抑揚で同じ発音で、自分の口に出して真似ていく。30分の練習の後には気分は既にディカプリオでしたね。

それでは、本日もKaggleで銅メダルを取ることを目指して一つ一つ進めていきましょう。前回は住宅価格を推定するCompetitionのデータをダウンロードしました。本日は、同Competitionに参加した先人たちのブログを読み、どうアプローチしてゴールを目指せば良いのか、理解していきましょう。
どうやら参加者固有のステップもありそうですが、Kaggleに参加する上でどうしても外せない基礎となるステップがありそうです。
- 動作環境の構築
- KaggleからCompetitionデータを取得
- データ概要の把握
- 外れ値の削除
- 前処理:欠損値処理
- 前処理:変数変換
- 目的変数の分布の確認、処理
- 特徴量の選択
- 機械学習
- モデルをKaggleへ提出
参考となるブログを以下に列挙しましょう。
https://www.kaggle.com/serigne/stacked-regressions-top-4-on-leaderboard
python初心者がkaggleのHousePriceコンペに参加してみた - Qiita
住宅価格を予測する〜Kaggle House Priceチュートリアルに挑む(その1) | キヨシの命題
不動産価格を機械学習で予測するKaggleに挑戦する [ベンチマーク編] | infomode
機械学習3ヶ月の初心者がKaggleHousingPriceに挑戦した(Top29%) 前半 - Qiita
Kaggleの練習問題(Regression)を解いてKagglerになる - Qiita
本日は、モデルを実行するための環境を構築しましょう。
以下の記事でも触れましたが、ローカルPCで機械学習を実行させると数時間かかる事もある、という話を良く聞きます。
それは、ローカルPC(僕はMacbookairを使っています。)のCPUでは、サクッとできないからなんですね。そこで、先人たちはGPU(Graphics Processing Unit)なるものを使っているらしいので、今回は、GPUをオンラインで使える環境を構築しましょう。
ということで、GPUが使える環境という事で良く使われているらしいGoogle Colaboratoryで環境を構築します。
こちらのブログを参考にしています。
Google Colaboratoryを開き、ウィンドウ下にある「NEW PYTHON 3 NOTEBOOK」をクリックします。

続いて、toolbarのRuntimeからChange runtime typeを選びます。

これで、先ずはGoogle Colaboratory上でコードを走らせる環境ができました。
続いて、KaggleからダウンロードしたデータをGoogle Colaboratory上で扱えるように設定します。Kaggleからダウンロードしたデータを解凍します。解凍したら「all」という名前のフォルダがあるはずです。それをGoogle Driveにアップロードしましょう。
そして、Google Colaboratoryに戻って頂いてpydriveをpipでインストールしましょう。pipの前に「!」をつける事を忘れないようにしましょう。「再生ボタン」を押すとコードが実行されます。

続いて、以下のコードを実行します。
実行すると、リンクが表示されるので、リンクをクリックし、Googleアカウントを選び、そこで表示されるコードをコピーします。コピーしたコードを、Google Colaboratoryにある「Enter verification code」のテキストボックスに入れます。

これにより、Google ColaboratoryからGoogle Driveへアクセスできる環境ができました。
続いて、Google Driveへアップロードしたファイル1つ1つをGoogle Colaboratory上で操作できるようにします。
先ほどアップロードした「all」というフォルダーをGoogle Drive上で開き、ファイルを右クリックし、「Get shareable link」をクリックします。

そして、リンクが表示されるので、表示されたリンクの「ID=」以降の部分をコピーします。
以下のコードをGoogle Colaboratory上で実行します。コピーしたIDを*に部分に入れましょう。以下のコードは3つのファイルを扱っているので、Google Drive上で、それぞれ3つのファイルから一つづつ「Get shareable link」でIDを取得しましょう。
これで、Google ColaboratoryからGoogle Drive上の特定のファイルを扱うための設定は終わりです。
実際に、扱えているのか見てみましょう。
Google Colaboratory上でpandasというライブラリをimportし、以下のコードを実行しましょう。


そうすると、テーブル上の最初の5行が確認できます。

これで、Google ColaboratoryからGoogle Drive上の特定のファイルを扱える、という事を確認できました。
次の記事では、早速データを見ていきましょう。
それでは、本日は以上でございます。
Kaggle 銅メダルへの道(初日)
こんにちは筋肉めがねです。
ドイツに来て数年経ちますが、ドイツ語をきちんと話せません。という事で、今年はドイツ語を話せるようになりたい、と考えてます。さて、勉強方法ですが、色々と方法があり、迷うところですね。そんなこんなで迷っていると、まつぼっくりちゃんから「英語を勉強した時と同じ方法でやってみたら。」と。なるほど、いつもいつも迷った時に目の前が開ける指針を与えてくれると感心しながら英語の勉強を振り返ってみました。そういえば、シャドーウィングという方法で英語を勉強していたな、と。具体的な方法については、明日書きましょう。

それでは、早速、Kaggleで銅メダルを取るため、本日から一つ一つ進めていきましょう。最近ドイツでの住宅事情が気になっているところなので、先ずはKaggleのプラットフォームで初心者用として準備されている「House Prices: Advanced Regression Techniques」のCompetitionを進めていきましょう。これは住宅の種々の情報から売価を予測するモデルを作り、そのモデルの精度を競うCompeitionですね。
本日は、Kaggleへのアカウント登録、そしてデータのダウンロードまで行いました。
ダウンロードしたデータの中身は、テストデータ、訓練データ、そしてsubmission exampleですね。submission exampleは以下の通りです。住宅のIDおよび住宅の価格を提出する、という事ですね。

ドイツにながーく住んでいると、気になってくるのは家、flatの価格ですね。
このモデルができた暁には、Immobilienscout24で掲載されているドイツの住宅の価格が妥当なものなのか、検証していきたいと思います。
それでは、本日は以上でございます。
2019年1月〜3月の目標
こんにちは、筋肉めがねです。
明けましておめでとうございます。読者の皆様は良い新年を迎えられたでしょうか。僕は幸運にも、まつぼっくりちゃん手作りのお節料理を頂く事ができました。ドイツに移住してきて彼此数年経ちますが、まさか新年にお節料理を食べる事ができるとは夢にも思っておりませんでしたが、2019年は夢のような出来事が現実となる一年のようです。

昨日12月31日に2018年10月〜12月の目標である「ゼロからはじめるDeep Learning」を終えました。そして、本日新年を迎えた事を機に、2019年1月〜3月の目標を設定します。
2019年1月〜3月
1月中にKaggleで銅メダル以上を取る。
3月末までにKaggleで銀メダル以上を取る。
それでは、明日から目標に向けて一つ一つ進めていきましょう。
2019年もどうぞよろしくお願い申し上げます。
筋肉めがね
ゼロから作るDeep Learning(最終日)
こんにちは、筋肉めがねです。
2018年10月1日から始めたこの「ゼロから作るDeep Learning」勉強シリーズもようやく最終日を迎えました。3ヶ月で本を一冊終わらせる、という目標に向けて取り組んで参りましたが、本日12月31日に、無事に最後の章である8章について書く事ができ、2019年を清々しい気持ちで迎える事ができそうです。

それでは、早速「ゼロから作るDeep Learning」について、最後の記事を書いていきましょう。本日は8章です。8章は、ディープラーニングを実装する事には重きを置いておらず、現在主流となっている技術の紹介、そしてディープラーニングが使われているアプリケーションの紹介ですね。
中でも「強化学習」という項目が気になったのでそれについて書いていきます。強化学習とは、「特定のタスクを達成するために必要な行動をコンピュータ自ら学習していく」ものです。そして、一連の行動の結果、与えられる報酬(期待値)を最大化させる行動を学習していきます。強化学習では、与えられた「環境」における「価値」を最大化させるようにエージェントに学習させます。
「強化学習」を取り入れたアプレケーションとしてAlphaGoが有名ですね。プロの囲碁棋士を人工知能が負かした、という事でとても大きな話題になりました。

本書でこれまで扱ってきたケースは「教師あり学習」と呼ばれるものでした。ニューラルネットワークへ訓練データを入力し、出力値と教師データを比較、差分を損失関数で計算し、損失関数の重みによる偏微分を勾配として求め、勾配方向へ重みを更新していく。
しかし、「強化学習」には教師データはありません。エージェントがある環境下で何らかの行動を起こし、その行動によって変化した環境から情報(報酬)を得る。その繰り返しによって、コンピュータが学習していきます。
今月12月に、AlphaGoを開発したDeep Mind(google傘下)から、Scienceにて新たに論文が発表されましたね。
Mindgameのルールを全く知らないAlphaZeroという人工知能が、外部から教えてもらう事なく、ゲームを繰り返し行う事で、ルールを自ら「学習」しています。チェスの人工知能として良く知られているStokfishという人工知能と、AlphaZeroがプレイしたところ、1000回のゲームの中で155回AlphaZeroが勝利し、6回負け、839回引き分けた、という事です。そして、プロの囲碁棋士を負かしたというAlphaGoに対してAlphaZeroが囲碁をプレイしたところ、61%の確率で勝利した、という事です。2年前に大きなニュースとなったAlphaGoを負かすというのは、技術の進歩はとても早いなと感嘆しますね。
以上で「ゼロから作るDeep Learning」勉強シリーズは以上でございます。雨の日も風の日も雪の日も、このブログを楽しみにしてくださった、そして更新する度に読んでくださった熱心な読者の方々に心より感謝申し上げます。
それでは、明日2019年1月1日より、新たなテーマでブログを書いていきます。
皆様方におかれましても良いお年をお迎えください。
筋肉めがね
ゼロから作るDeep Learning(24日目)
こんにちは、筋肉めがねです。
2016年1月にEuropean Commissionから発表されたAnti-Tax avoidance packageによると、EU域において、各国当局が企業からの法人税をより適切に徴収するための仕組みづくりの一環として、2019年1月1日より、新たに5つのルールが施行されます。そのうちの一つであるExit taxは、欧州に支店を持つ日系企業の頭を悩ませる種となっております。
EU域のある国において既にビジネスをしており、ある程度の利益を出している企業の場合、現地当局に税金を納めているいますよね。例えばその国からビジネスを撤退する、という事になると、撤退に伴いExit taxなるものを現地当局に納める必要がある、というものです。企業がビジネスの形態をシフトしていくフェーズでは、既存の事業を見直し、必要なところを残し、必要のないところはビジネスを閉じる、という選択と集中が必要で、そのフェーズではある程度の痛みは伴うかもしれません。その痛みが許容できるものなのか、企業の体力を考慮して、valuationをした上で次に進んでいくべきですね。

出典:
それでは、本日も「ゼロから作るDeep Learning」を進めていきましょう。
本日は7章です。畳み込みニューラルネットワークです。この記事で7章について書き、そして、次の記事で8章について書きましょう。3ヶ月にわたって書いてきた「ゼロから作るDeep Learning」の勉強ブログも終わりが見えてきました。
さて、畳み込みニューラルネットワークです。良く聞く名前ですね。では一体全体なんなのか。「畳み込み」とは、Wikiによると関数gを並行移動しながら関数fに重ね足し合わせる二項演算とあります。
Wikiに載っているシミュレーションがとても分かりやすいですね。関数gを並行移動させながら関数fに重ね足し合わせると、重なっている部分が黄色の領域となっています。そして、下のグラフでは、その黄色の領域の面積を縦軸にとって、時間の経過とともに面積がどう変わるかを表していますね。

出典:
https://ja.wikipedia.org/wiki/%E7%95%B3%E3%81%BF%E8%BE%BC%E3%81%BF
この畳み込み演算を利用して、特に画像認識、および音声認識の分野で使われている手法が畳み込みニューラルネットワークです。とても分かりやすく説明しているブログがありましたので紹介します。
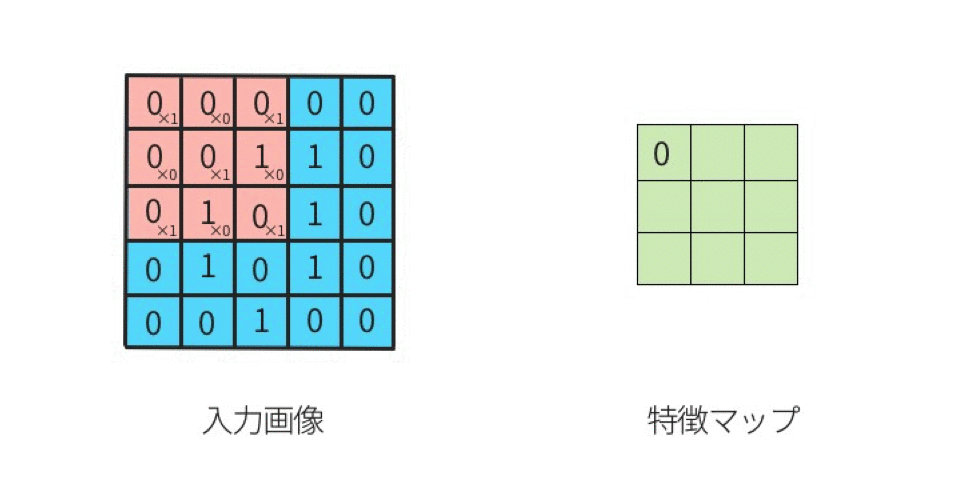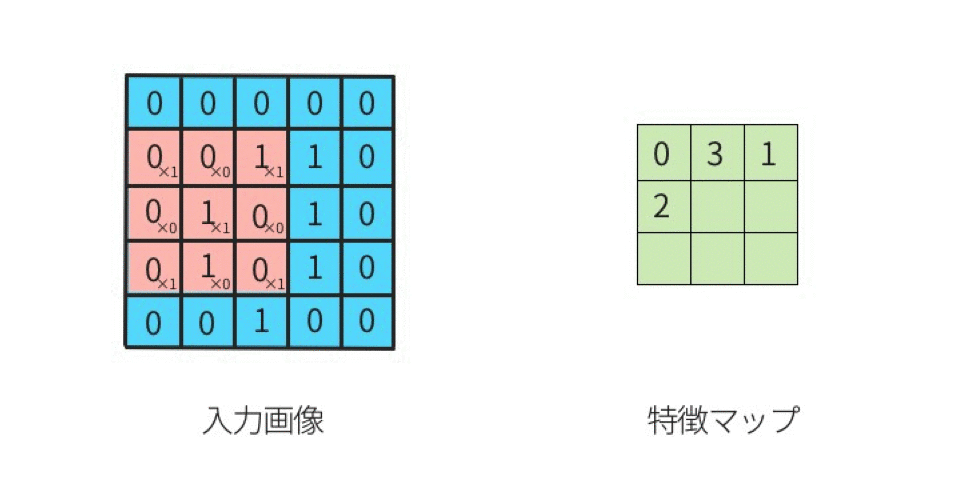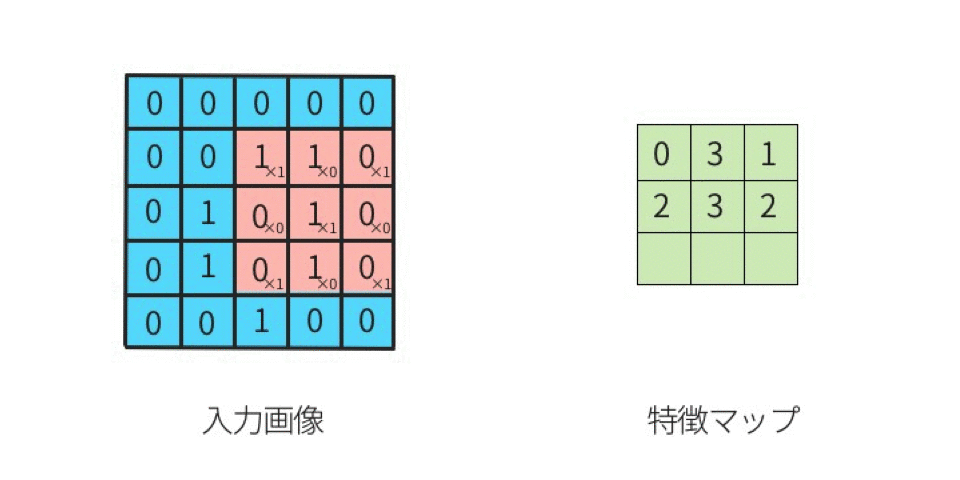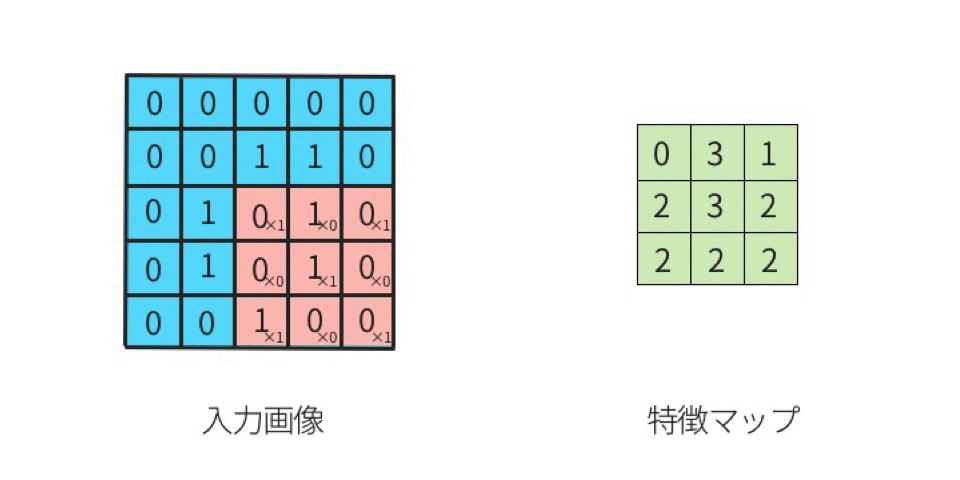
出典:定番のConvolutional Neural Networkをゼロから理解する - DeepAge
ポイントは入力データに対してフィルターを適用し、フィルターを複数マス毎、動かしていき、その時、入力データとフィルターが重なっている領域において、条件を見たす数値を抽出し、それを特徴マップとして出力していくんですね。これがざっくりとして畳み込みニューラルネットワークの原理です。
先ずは実際に、手書き数値の認識を行う、畳み込みニューラルネットワーク(Convolutional Neural Network)を実装してみましょう。
実装結果、そしてコードを以下に示します。
ちなみにこの結果を得るために、terminal上でコードを1時間ぐらい走らせております。良く巷で聞く「学習」に時間がかかる、というのはこの事なんですね。


結果、テストデータの認識率は98.9%というニューラルネットワークを作る事ができました。
こちらがコードです。
先ずはニューラルネットワークの実装です。
続いてMNISTデータセットを用いた実験です。
特に大事な事は、CNNでは、畳み込み層、活性化関数、プーリング層が連なるセットが複数並ぶ、という事、そして、畳み込み層では、画像上の各位置毎に特徴抽出を行っており、そしてプーリング層では、ロバスト性を確保するために補助的に導入している、とう事です。プーリング層の役割のうち、主に使用されるのはMaxプーリングと呼ばれるものです。それは、画像のある地域における最大値を抽出し、出力する事です。
例えば以下の入力データがある場合、緑色の位置にある0, 3, 1, 6の最大値は6ですね。これを一つ一つの画素と捉えた場合、この配置が3, 6, 1, 0になっても最大値は6ですね。つまり、特徴が画像上で移動していたとしても、抽出される特徴量は安定した値となる、という事です。入力データの小さなズレに対して、プーリングは同じような結果を返すんですね。
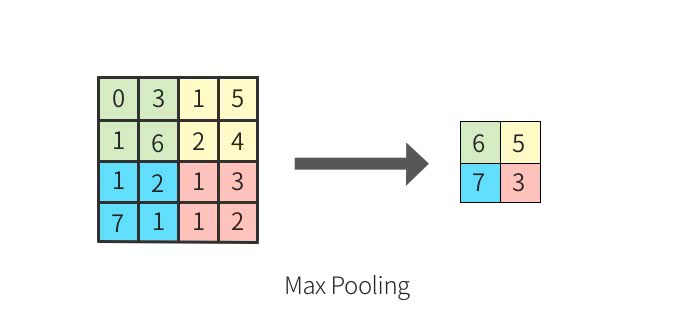
出典:定番のConvolutional Neural Networkをゼロから理解する - DeepAge
例えば下の2枚の犬の写真は少しずれていますよね。それでも、同じ結果を返してくれるようにニューラルネットワークを安定させているのがプーリング層、というわけです。

出典:
https://jp.mathworks.com/discovery/convolutional-neural-network.html
これで7章は以上です。次は8章ですね。そして、この「ゼロから作るDeep Learning」勉強シリーズも最後となります。
それでは、本日は以上でございます。
ゼロから作るDeep Learning(23日目)
こんにちは、筋肉めがねです。
ドイツに移住してきて数年経ちますが、ドイツでの決まりごとを新しく知る機会に触れると、おっ、と感じますね。ドイツでは、12月29日から31日の3日間は、花火、爆竹の販売が許可されているらしんです。もともと、花火、爆竹それ自体は、戦時中の爆弾を彷彿とさせる、という理由で禁止されているらしんですが、この時期ばかりはドイツ政府も許可を出している、という事です。そして、12月31日、1月1日の2日間については、花火、爆竹の使用が許可されている、という事です。
花火と言えば、僕は線香花火を思い出します。8月のお盆の時期に、迎え火、そして送り火をする際に、従兄弟たちと線香線香をしていた事がとても良い記憶として残っています。はじめは静かに、そして少しずつ勢いを増し、盛大に周りを明るく照らした後は、少しずつその存在感を弱めていく。とても儚く、それでいて素敵な花火ですよね。

それでは、本日も「ゼロから作るDeep Learning」を進めていきましょう。本日は、6章最後の記事です。
前回の記事では、過学習を抑制する手法の一つとしてWeight decayを紹介しました。本日は、もう一つ本書で紹介されているdropoutについて書き、そしてハイパーパラメータの最適化について書いていきます。
Dropoutとは、ニューラルネットワークが「学習」するフェーズにおいて、複数あるニューロンのうち、幾つかのニューロンをランダムに不活性させる事で、つまり動かなくする事で信号の伝達を抑制させるものです。そして、順伝播時に、信号が伝わらなかったニューロンについては、逆伝播時にも、そこで信号はストップします。
ここで、改めて順伝播と逆伝播の意味をおさらいしておきます。
先ずは、ニューラルネットワークの「学習」ステップをおさらいしましょう。
1. 訓練データをニューラルネットワークに投げ込み、層から層へと信号を伝達していき、最後の出力層から出てくるデータを、教師データと比較します。
*その時の誤差を小さくしていく事こそが、ニューラルネットワークの「学習」の目的です。すべき事は、重みパラメータやバイアスを変化させた時の、誤差の変化量を小さくする事です。つまり、誤差の重みによる微分を小さくしていくんですね。そして、このステップ1こそが順伝播です。
2. 続いて、誤差逆伝播法を用いて、各重みパラメータに関する損失関数の勾配を求め、その勾配方向に重みパラメータを更新していくわけですね。これが、逆伝播ですね。
そもそもあるニューロンを不活性させると何が嬉しいか、というと、ニューラルネットワークが簡単になるわけですね。つまり複雑さが減る、という事です。過学習が起きる一つの原因はニューラルネットワークの複雑性にありました。モデルが複雑になればなるほど、訓練データ群の外れ値にまでも適合してしまうモデルができあがってしまいます。そこで、モデルを簡素化させるわけです。
そもそもDropoutの何が嬉しいか、というと、「学習」の1サイクル(入力データをニューラルネットワークに入れ、データを出力し、それを教師データと比較し、そして誤差逆伝播法により重みパラメータを更新する)毎に、ランダムに異なるニューロンを不活性化させる、という事です。つまり、サイクル毎に、見た目上異なるニューラルネットワークを用いて「学習」させている場合と同じような効果を得られるわけですね。機械学習の分野では、アンサンブル学習と呼ぶものがあり、それは、似通った異なる複数のニューラルネットワークに対して同様の訓練データを使い、「学習」させ、テストの時には、その出力の平均をとる、というものです。Dropoutでは、アンサンブル学習を擬似的に実現しているわけですね。
続いて、ハイパーパラメータの最適化です。ハイパーパラメータとは重みパラメータ以外の、ニューラルネットワークにおける変数ですね。例えばニューロンの数や、以下の式における学習率ηですね。
w ← w - η * (∂L/∂W)
本書では学習係数とweight decay係数の最適な値を求める実験を行っていますね。
以下、テスト結果とコードです。
訓練データを破線で、テストデータを実線で表しています。そして、100回ランダムに学数係数とweight decay係数を決め、それらの100セットを使って、そしてMNISTのデータセットを使って、ニューラルネットワークに学習させた結果、テストデータの認識精度が高くなった順からBest1...と並べた結果です。

Best1から3までのケースの学習係数lrとweight decay係数は以下の通りです。
結果、学習がうまく進むのは、学習係数が0.0045から0.0079であり、そしてweight decay係数が10^-5から10^-8である事がわかります。例えばこういう手法で最適なハイパーパラメータを探索していくんですね。

こちらがコードです。
これで6章は以上でございます。次は7章ですね。
それでは、本日は以上でございます。