こんにちは、筋肉めがねです。
2016年1月にEuropean Commissionから発表されたAnti-Tax avoidance packageによると、EU域において、各国当局が企業からの法人税をより適切に徴収するための仕組みづくりの一環として、2019年1月1日より、新たに5つのルールが施行されます。そのうちの一つであるExit taxは、欧州に支店を持つ日系企業の頭を悩ませる種となっております。
EU域のある国において既にビジネスをしており、ある程度の利益を出している企業の場合、現地当局に税金を納めているいますよね。例えばその国からビジネスを撤退する、という事になると、撤退に伴いExit taxなるものを現地当局に納める必要がある、というものです。企業がビジネスの形態をシフトしていくフェーズでは、既存の事業を見直し、必要なところを残し、必要のないところはビジネスを閉じる、という選択と集中が必要で、そのフェーズではある程度の痛みは伴うかもしれません。その痛みが許容できるものなのか、企業の体力を考慮して、valuationをした上で次に進んでいくべきですね。

出典:
https://ec.europa.eu/taxation_customs/business/company-tax/anti-tax-avoidance-package/anti-tax-avoidance-directive_en
それでは、本日も「ゼロから作るDeep Learning」を進めていきましょう。
本日は7章です。畳み込みニューラルネットワークです。この記事で7章について書き、そして、次の記事で8章について書きましょう。3ヶ月にわたって書いてきた「ゼロから作るDeep Learning」の勉強ブログも終わりが見えてきました。
さて、畳み込みニューラルネットワークです。良く聞く名前ですね。では一体全体なんなのか。「畳み込み」とは、Wikiによると関数gを並行移動しながら関数fに重ね足し合わせる二項演算とあります。
Wikiに載っているシミュレーションがとても分かりやすいですね。関数gを並行移動させながら関数fに重ね足し合わせると、重なっている部分が黄色の領域となっています。そして、下のグラフでは、その黄色の領域の面積を縦軸にとって、時間の経過とともに面積がどう変わるかを表していますね。

出典:
https://ja.wikipedia.org/wiki/%E7%95%B3%E3%81%BF%E8%BE%BC%E3%81%BF
この畳み込み演算を利用して、特に画像認識、および音声認識の分野で使われている手法が畳み込みニューラルネットワークです。とても分かりやすく説明しているブログがありましたので紹介します。
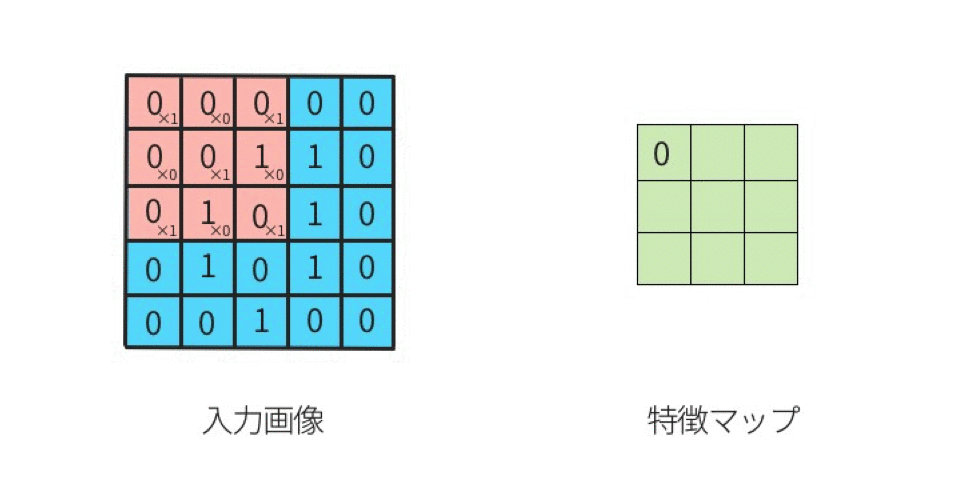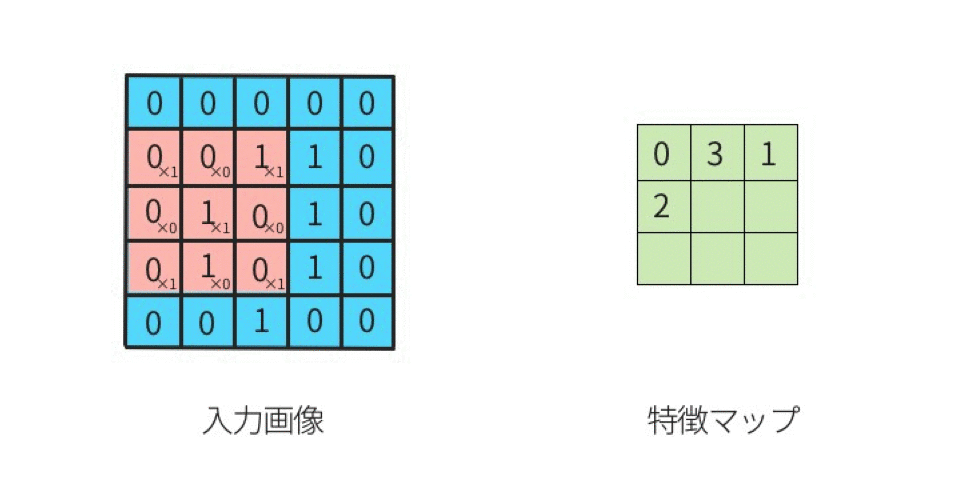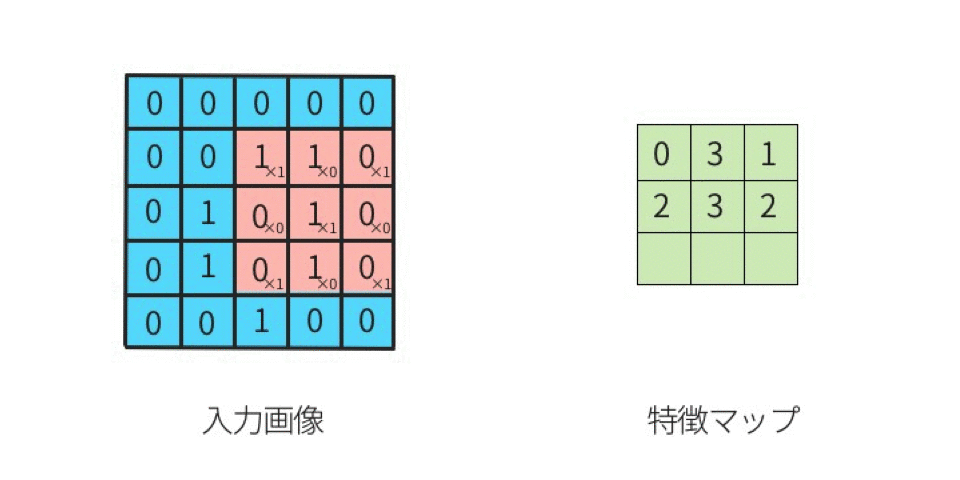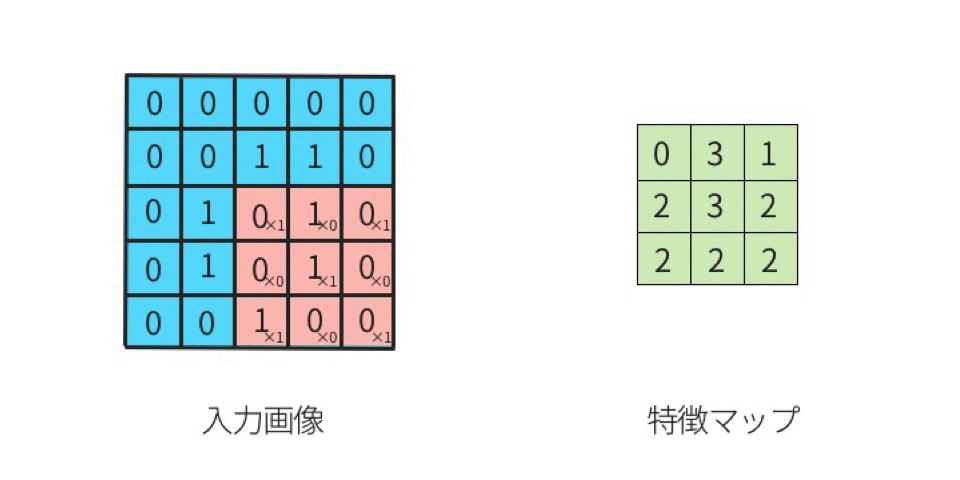
出典:定番のConvolutional Neural Networkをゼロから理解する - DeepAge
ポイントは入力データに対してフィルターを適用し、フィルターを複数マス毎、動かしていき、その時、入力データとフィルターが重なっている領域において、条件を見たす数値を抽出し、それを特徴マップとして出力していくんですね。これがざっくりとして畳み込みニューラルネットワークの原理です。
先ずは実際に、手書き数値の認識を行う、畳み込みニューラルネットワーク(Convolutional Neural Network)を実装してみましょう。
実装結果、そしてコードを以下に示します。
ちなみにこの結果を得るために、terminal上でコードを1時間ぐらい走らせております。良く巷で聞く「学習」に時間がかかる、というのはこの事なんですね。


結果、テストデータの認識率は98.9%というニューラルネットワークを作る事ができました。
こちらがコードです。
先ずはニューラルネットワークの実装です。
import sys, os
sys.path.append(os.pardir)
import pickle
import numpy as np
from collections import OrderedDict
from common.layers import *
from common.gradient import numerical_gradient
class SimpleConvNet:
"""単純なConvNet
conv - relu - pool - affine - relu - affine - softmax
Parameters
----------
input_size : 入力サイズ(MNISTの場合は784)
hidden_size_list : 隠れ層のニューロンの数のリスト(e.g. [100, 100, 100])
output_size : 出力サイズ(MNISTの場合は10)
activation : 'relu' or 'sigmoid'
weight_init_std : 重みの標準偏差を指定(e.g. 0.01)
'relu'または'he'を指定した場合は「Heの初期値」を設定
'sigmoid'または'xavier'を指定した場合は「Xavierの初期値」を設定
"""
def __init__(self, input_dim=(1, 28, 28),
conv_param={'filter_num':30, 'filter_size':5, 'pad':0, 'stride':1},
hidden_size=100, output_size=10, weight_init_std=0.01):
filter_num = conv_param['filter_num']
filter_size = conv_param['filter_size']
filter_pad = conv_param['pad']
filter_stride = conv_param['stride']
input_size = input_dim[1]
conv_output_size = (input_size - filter_size + 2*filter_pad) / filter_stride + 1
pool_output_size = int(filter_num * (conv_output_size/2) * (conv_output_size/2))
self.params = {}
self.params['W1'] = weight_init_std * \
np.random.randn(filter_num, input_dim[0], filter_size, filter_size)
self.params['b1'] = np.zeros(filter_num)
self.params['W2'] = weight_init_std * \
np.random.randn(pool_output_size, hidden_size)
self.params['b2'] = np.zeros(hidden_size)
self.params['W3'] = weight_init_std * \
np.random.randn(hidden_size, output_size)
self.params['b3'] = np.zeros(output_size)
self.layers = OrderedDict()
self.layers['Conv1'] = Convolution(self.params['W1'], self.params['b1'],
conv_param['stride'], conv_param['pad'])
self.layers['Relu1'] = Relu()
self.layers['Pool1'] = Pooling(pool_h=2, pool_w=2, stride=2)
self.layers['Affine1'] = Affine(self.params['W2'], self.params['b2'])
self.layers['Relu2'] = Relu()
self.layers['Affine2'] = Affine(self.params['W3'], self.params['b3'])
self.last_layer = SoftmaxWithLoss()
def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x)
return x
def loss(self, x, t):
"""損失関数を求める
引数のxは入力データ、tは教師ラベル
"""
y = self.predict(x)
return self.last_layer.forward(y, t)
def accuracy(self, x, t, batch_size=100):
if t.ndim != 1 : t = np.argmax(t, axis=1)
acc = 0.0
for i in range(int(x.shape[0] / batch_size)):
tx = x[i*batch_size:(i+1)*batch_size]
tt = t[i*batch_size:(i+1)*batch_size]
y = self.predict(tx)
y = np.argmax(y, axis=1)
acc += np.sum(y == tt)
return acc / x.shape[0]
def numerical_gradient(self, x, t):
"""勾配を求める(数値微分)
Parameters
----------
x : 入力データ
t : 教師ラベル
Returns
-------
各層の勾配を持ったディクショナリ変数
grads['W1']、grads['W2']、...は各層の重み
grads['b1']、grads['b2']、...は各層のバイアス
"""
loss_w = lambda w: self.loss(x, t)
grads = {}
for idx in (1, 2, 3):
grads['W' + str(idx)] = numerical_gradient(loss_w, self.params['W' + str(idx)])
grads['b' + str(idx)] = numerical_gradient(loss_w, self.params['b' + str(idx)])
return grads
def gradient(self, x, t):
"""勾配を求める(誤差逆伝搬法)
Parameters
----------
x : 入力データ
t : 教師ラベル
Returns
-------
各層の勾配を持ったディクショナリ変数
grads['W1']、grads['W2']、...は各層の重み
grads['b1']、grads['b2']、...は各層のバイアス
"""
self.loss(x, t)
dout = 1
dout = self.last_layer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
grads = {}
grads['W1'], grads['b1'] = self.layers['Conv1'].dW, self.layers['Conv1'].db
grads['W2'], grads['b2'] = self.layers['Affine1'].dW, self.layers['Affine1'].db
grads['W3'], grads['b3'] = self.layers['Affine2'].dW, self.layers['Affine2'].db
return grads
def save_params(self, file_name="params.pkl"):
params = {}
for key, val in self.params.items():
params[key] = val
with open(file_name, 'wb') as f:
pickle.dump(params, f)
def load_params(self, file_name="params.pkl"):
with open(file_name, 'rb') as f:
params = pickle.load(f)
for key, val in params.items():
self.params[key] = val
for i, key in enumerate(['Conv1', 'Affine1', 'Affine2']):
self.layers[key].W = self.params['W' + str(i+1)]
self.layers[key].b = self.params['b' + str(i+1)]
続いてMNISTデータセットを用いた実験です。
import sys, os
sys.path.append(os.pardir)
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from simple_convnet import SimpleConvNet
from common.trainer import Trainer
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=False)
max_epochs = 20
network = SimpleConvNet(input_dim=(1,28,28),
conv_param = {'filter_num': 30, 'filter_size': 5, 'pad': 0, 'stride': 1},
hidden_size=100, output_size=10, weight_init_std=0.01)
trainer = Trainer(network, x_train, t_train, x_test, t_test,
epochs=max_epochs, mini_batch_size=100,
optimizer='Adam', optimizer_param={'lr': 0.001},
evaluate_sample_num_per_epoch=1000)
trainer.train()
network.save_params("params.pkl")
print("Saved Network Parameters!")
markers = {'train': 'o', 'test': 's'}
x = np.arange(max_epochs)
plt.plot(x, trainer.train_acc_list, marker='o', label='train', markevery=2)
plt.plot(x, trainer.test_acc_list, marker='s', label='test', markevery=2)
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()
特に大事な事は、CNNでは、畳み込み層、活性化関数、プーリング層が連なるセットが複数並ぶ、という事、そして、畳み込み層では、画像上の各位置毎に特徴抽出を行っており、そしてプーリング層では、ロバスト性を確保するために補助的に導入している、とう事です。プーリング層の役割のうち、主に使用されるのはMaxプーリングと呼ばれるものです。それは、画像のある地域における最大値を抽出し、出力する事です。
例えば以下の入力データがある場合、緑色の位置にある0, 3, 1, 6の最大値は6ですね。これを一つ一つの画素と捉えた場合、この配置が3, 6, 1, 0になっても最大値は6ですね。つまり、特徴が画像上で移動していたとしても、抽出される特徴量は安定した値となる、という事です。入力データの小さなズレに対して、プーリングは同じような結果を返すんですね。
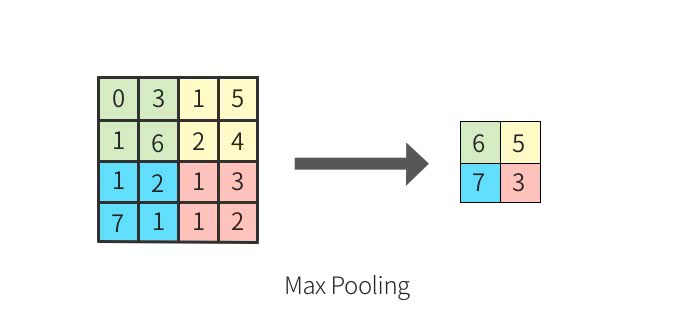
出典:定番のConvolutional Neural Networkをゼロから理解する - DeepAge
例えば下の2枚の犬の写真は少しずれていますよね。それでも、同じ結果を返してくれるようにニューラルネットワークを安定させているのがプーリング層、というわけです。

出典:
https://jp.mathworks.com/discovery/convolutional-neural-network.html
これで7章は以上です。次は8章ですね。そして、この「ゼロから作るDeep Learning」勉強シリーズも最後となります。
それでは、本日は以上でございます。

にほんブログ村

Pythonランキング